Ця настанова для розробників, що вже знайомі з основами побудови застосувань, та тепер бажають знати кращі практики та рекомендовану архитектуру для побудови надійних застосувань промислової якості.
Загальні проблеми, з якими стикаються розробники застосувань
На відміну від своїх десктопних співродичів, які, в більшості випадків, мають одну точку входу в вигляді іконки запуску, та роблять як єдиний монолітний процес, застосування Android мають значно більш складну структуру. Типове застосування Android побудоване з декількох app компонент, включаючи активності, фрагменти, серсіви, провайдери вмісту та широкополосні отримувачі.
Більшість з ціх застосувань декларовані в app маніфесті, що використовується Android OS для вирішення, як інтегрувати ваше застосування в загальний користувацький досвід роботи з пристроєм. В той час, як зазначено вище, десктопне застосування традиційно робить як монолітний процес, правильно написане застосування Android має бути значно гнучкішим, по мірі того, як користувач прокладає власний шлях поміж застосувань на пристрої, постійно переключаючи потоки та завдання.
Наприклад, розглянемо, що трапиться, коли ви поділяєте фото в вашій улюбленій соціальній мережі. Застосування перемикає намір-інтент камери, з якого Android OS запускає застосування камери для обробки запиту. В цій точці, користувач залишає застосування соціальної мережі, але його досвід не має цього усвідомлювати. Застосування камери, в свою чергу, може запустити інші інтенти, як запустити обирач файлів, що може запустити інше застосування. З часом користувач повернеться до застосування соціальної мережі, та світлина буде передана. Також, користувач може бути перерваний телефонним викликом в любій точці цього процессу, щоб поширити фото після завершення телефонного виклику.
В Android ця поведінка переривання застосувань, так що ваше застосування мусить обрболяти ці потоки коректно. Майте на увазі, що мобільні пристрої обмежені в ресурсах, так що в любий час операційна система може потребувати вбити деякі застосування, щоб вивільнити простір для нових.
Смисл всього цього в тому, що компоненти вашого застосування можуть бути запущені індивідуально в довільному порядку, та можуть бути знищені в кожну мить, користувачем або системою. Оскільки компоненти застосування є ефемірними, та їх життєвий цикл (коли воні створюються та руйнуються) не контролюється вами, ви не повинні зберігати жодні дані застосування або стан в компонентах вашого застосування, та компоненти вашого застосування не повинні залежати один від одного.
Загальні архитектурні принципи
Якщо ви не можете використовувати компоненти застосування для збегірання даних та стану застосування, як ми маємо структурувати застосування?
Найбільш важлива річ, на якій ви маєте зфокусуватись, є розділення
концепцій вашого застосування. Є загальною помилкою
писати весь ваш код в Activity
або Fragment.
Любий код, що не обробляє UI, або не взаємодіє з операційною системою,
не повинно бути в ціх класах. Утримання їх такими утисненими, як це
можливе, дозволить вам уникнути багато проблем, пов'язаних з життєвим
циклом. Не забувайте, що ви не володієте ціма класами, вони
лише класи-клей, що лише втілюють контракт між OS, та вашим
застосуванням. Android OS може зруйнувати їх в любий час, базуючись на
взаємодії користувача, або інших факторах, як надостатня пам'ять. Краше
мінімізувати вашу залежність від них, щоб провадити солідний
користувацький досвід.
Другий важливий принцип в тому, що вам треба будувати ваш UI від моделі, бажано стійкої моделі. Стійкість є ідеальною з двох причин: ваші користувачі не втратяться дані, якщо ваша OS зруйнує ваше застосування, щоб вивільнити ресурси, та ваше застосування буде продовжувати роботу, навіть коли ваше мережеве з'єднання слабке або відсутнє. Моделі є компонентами, що відповідні за обробку даних для застосування. Вони незалежні від Views та компонент застосування, і, таким чином, вони ізольовані від проблем життєвого циклу ціх компонент. Утримуючи код UI простим, та вільним від логіки застосування, робить керування простішим. Базуючи ваше застосування на класах моделі з гарно визначеною відповідальністю по обробці даних, робить їх придатними для тестування, та ваше застосування узгодженим.
Рекомендована архитектура застосування
В цьому розділі ми подемонструємо, як структурувати застосування, використовуючи Архитектурні компоненти, через проходження випадку-прикладу.
Уявіть, що ми будуємо UI, що показує профіль користувача. Цей користувацький профіль буде підтягуватись з нашого власного бекенду через REST API.
Побудова користувацького інтерфейсу
UI буде складатись з фрагменту UserProfileFragment.java,
та його відповідного файлу розташування user_profile_layout.xml.
Щоб розробити UI, наша модель даних має зберігати два елементи даних.
- ID користувача: Ідентифікатор для користувача. Краще передавати цю інформацію у фрагмент з використанням аргументів фрагменту. Якщо Android OS зруйнує ваш процес, ця інформація буде збережена, так що цей id буде доступним наступного разу, коли ваше застосування буде рестартоване.
- Об'єкт User: POJO, що зберігає дані користувача.
Ми будемо створювати UserProfileViewModel на базі класу ViewModel,
що буде зберігати цю інформацію.
ViewModel провадить дані для окремого компоненту UI, такого, як фрагмент або активність, та обробляє комунікацію з бізнес-частиною обробки даних, тобто викликами інших компонент для завантаження даних або передачі модифікацій користувача. ViewModel не знає щодо View, та не має впливу від змін конфігурації, таких, як перебудова активності через повертання пристрою.
Тепер ми маємо три файли.
user_profile.xml: Визначення UI для екрана.UserProfileViewModel.java: Клас, що готує дані для UI.UserProfileFragment.java: UI контролер, що відображує дані в ViewModel, та реагує на взаємодію з користувачем.
Нижче наша початкова реалізація (файл розташування для простоти опущений):
public class UserProfileViewModel extends ViewModel {
private String userId;
private User user;
public void init(String userId) {
this.userId = userId;
}
public User getUser() {
return user;
}
}
public class UserProfileFragment extends Fragment {
private static final String UID_KEY = "uid";
private UserProfileViewModel viewModel;
@Override
public void onActivityCreated(@Nullable Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
String userId = getArguments().getString(UID_KEY);
viewModel = ViewModelProviders.of(this).get(UserProfileViewModel.class);
viewModel.init(userId);
}
@Override
public View onCreateView(LayoutInflater inflater,
@Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {
return inflater.inflate(R.layout.user_profile, container, false);
}
}
Тепер, коли ми маємо ці три модулі коду, як пов'язати їх разом? В кінці кінців, коли встановлюється поле користувача в ViewModel, нам треба спосіб поінформувати UI. Це те, де з'являється клас LiveData.
LiveData є прозорий контейнер даних. Він дозволяє компонентам вашого застосування досліджувати об'єкти
LiveDataщодо змін без створення явних та жорстких шляхів залежностей між ними. LiveData також поважає стан життєвого циклу компонент вашого застосування (активностей, фрагментів, сервісів), та робить правильні речі для запобігання утічкам об'єкта, так що ваше застосування не споживає більше пам'яті.
Тепер ми заміщуємо поле User в UserProfileViewModel
на LiveData<User>, так що фрагмент може бути
поінформований, коли дані будуть оновлені. Велика річ щодо LiveData
в тому, що він поінформований про життєвий цикл, та буде автоматично
очищувати посилання, коли вони більше не потрібні.
public class UserProfileViewModel extends ViewModel {
...
private User user;
private LiveData<User> user;
public LiveData<User> getUser() {
return user;
}
}
Тепер ми модифікуємо UserProfileFragment для нагляду за
даними та оновлення UI.
@Override
public void onActivityCreated(@Nullable Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
viewModel.getUser().observe(this, user -> {
// оновлення UI
});
}
Кожного разу, коли дані користувача оновлюються, буде викликаний зворотній виклик onChanged, та UI буде оновлений.
Якщо ви знайомі з іншими бібліотеками, де використовуютсья бібліотеки
для нагляду, ви можете помітити, що ми не перекрили метод фрагмента onStop()
для припинення нагляду за даними. Це не потрібно для LiveData, оскільки
він в курсі життєвого циклу, що означає, що він не викликатиме зворотній
виклик, якщо фрагмент не знаходиться в активному стані (отрав onStart(),
але не отримував onStop()).
LiveData також буде автоматично видаляти наглядач-обсервер, коли
фрагмент отримує onDestroy().
Ми також не робимо нічого особливого для обробки змін конфігурації (наприклад, коли користувач обертає екран). ViewModel автоматично відновлюється при зміні конфігурації, так що коли новий фрагмент приходить до життя, він буде отримувати той самий примірник ViewModel, та зворотній виклик буде викликаний безпосередньо з поточними даними. Це та причина, чому ViewModels не має прямо посилатись на View; вони можуть пережити життєвий цикл View. Дивіться життєвий цикл ViewModel.
Підтягування даних
Тепер ми поєднали ViewModel з фрагментом, але як ViewModel підтягує дані користувача? В цьому прикладі ми вважаємо, що наш бекенд провадить REST API. Ми будемо викоистовувати бібліотеку Retrofit для доступу до нашого бекенду, хоча ви вільні використовувати іншу бібліотеку, що прислуговуєтсья тій самій цілі.
Ось наш retrofit Webservice, що комунікує з нашим
бекендомt:
public interface Webservice {
/**
* @GET декларує запит HTTP GET
* @Path("user") анотація на параметрі userId її як заміну для
* замінника {user} в шляху @GET
*/
@GET("/users/{user}")
Call<User> getUser(@Path("user") String userId);
}
Природна реалізація ViewModel може напряму викликати Webservice,
щоб підтягнути дані, та присвоїти їх назад об'єкту користувача. Навіть
хоча це працює, вашому застосуванню буде складно керувати цім по мірі
зростання. Це надає багато відповідальності класу ViewModel, що іде
всупереч принципу розділення концепцій, який ми згадували
раніше. Додатково, сфера впливу ViewModel прив'язаний до життєвого циклу
Activity
або Fragment,
так що втрата даних, коли життєвй цикл завершиться, стане поганою
новиною для користувача. Замість цього, наш ViewModel буде делегавувати
цю роботу довому модулю, Repository.
Repository модулі відповідають за обробку операцій з даними. Вони провадять чистий API до загалу застосування. Вони знають, коли отримувати дані від яких викликів API, щоб оновлювати дані. Ви можете розглядати їх як медіатори між різними джерелами даних (модель стійкості, веб сервіс, кеш, тощо).
Клас UserRepository нижче використовує WebService
to fetch the user data item.
public class UserRepository {
private Webservice webservice;
// ...
public LiveData<User> getUser(int userId) {
// This is not an optimal implementation, we'll fix it below
final MutableLiveData<User> data = new MutableLiveData<>();
webservice.getUser(userId).enqueue(new Callback<User>() {
@Override
public void onResponse(Call<User> call, Response<User> response) {
// error case is left out for brevity
data.setValue(response.body());
}
});
return data;
}
}
Навіть якщо модуль репозиторію виглядає непотрібним, він
прислуговується важливому призначенні; він абстрагує джерела даних з
решти застосування. Тепер ViewModel не знає, що дані отримуються від Webservice,
що означає, що ми можемо змінити його на іншу реалізацію в разі потреби.
Керування залежностями між компоннетами:
Клас UserRepository вище потребує примірник Webservice
для своєї роботи. Ми можемо просто створити його, але для цього треба
знати залежності класу Webservice для його конструювання.
Це може значно ускладнити код та привести до його дублікації (тобто,
кожний клас, що потребує примірник Webservice, буде
потребувати знання, як сконструювати його, разом з залежностями).
Додатково UserRepository, можливо, не є єдиним класом, що
потребує Webservice. Якщо кожний клас створюватиме новий WebService,
це може дуже навантажувати ресурси.
Існують два шаблони, що ви можете використовувати для обходу цієї проблеми:
- Dependency Injection: Введення залежностей, або Dependency Injection, скорочено DI, дозволяє класам визначати свої свої залежності без їх побудови. Під час виконання інший клас відповідає за провадження ціх залежностей. Ми рекомендуємо бібліотеку Google Dagger 2 для реалізації введення залежності в застосування Android. Dagger 2 automatically constructs objects by walking the dependency tree and provides compile time guarantees on dependencies.
- Service Locator: Локатор сервісів, або Service Locator, скорочено SL, провадить реєстр, де класи можуть отримати свої залежності, замість того, щоб конструювати їх. Це відносно простіше до реалізації, ніж DI, так що коли ви не дружите з DI, використовуйте замість цього Service Locator.
Ці шаблони дозволяють вам маштабувати ваш код, оскільки вони провадять прозорі шаблони для керування залежностями, без дублікації кода або доданої складності. Обоє з них також дозволяють заміну реалізацій для тестування; це одна з головних вигод з їх використання.
В цьому прикладі ми збираємось використовувати Dagger 2 для керумання залежностями.
Поєднання ViewModel та репозиторію
Тепер ми модифікуємо наш UserProfileViewModel для
використання з репозиторієм.
public class UserProfileViewModel extends ViewModel {
private LiveData<User> user;
private UserRepository userRepo;
@Inject // параметр UserRepository провадиться Dagger 2
public UserProfileViewModel(UserRepository userRepo) {
this.userRepo = userRepo;
}
public void init(String userId) {
if (this.user != null) {
// ViewModel стврюється для кожного Fragment,
// так що ми знаємо, що userId не змінився
return;
}
user = userRepo.getUser(userId);
}
public LiveData<User> getUser() {
return this.user;
}
}
Кешування даних
Реалізація репозиторію вище гарна для абстрагування виклику до веб сервісу, але оскільки вона покладається тільки на одне джерело даних, вона не дуже функціональна.
Проблема з реалізацією UserRepository вище в тому, що
після отримання даних вона ніде їх не зберігає. Якщо користувач полишає
UserProfileFragment, та потім повертається до нього, дані
будуть отримані повторно. Це погано з двох причин: це призводить до
втрати дорогоцінного мережевого трафіку, та примушує користувача
очікувати завершення нового запиту. Щоб владнати це, ми додамо нове
джерело даних до нашого UserRepository, що буде кешувати
об'єкти User в пам'яті.
@Singleton // інформує Dagger, що цей клас треба конструювати тільки один раз
public class UserRepository {
private Webservice webservice;
// простий кеш в пам'яті, деталі випущені для скорочення
private UserCache userCache;
public LiveData<User> getUser(String userId) {
LiveData<User> cached = userCache.get(userId);
if (cached != null) {
return cached;
}
final MutableLiveData<User> data = new MutableLiveData<>();
userCache.put(userId, data);
// це все ще не оптімально, але краще ніж раніше.
// повна реалізація має також обробляти випадки помилок.
webservice.getUser(userId).enqueue(new Callback<User>() {
@Override
public void onResponse(Call<User> call, Response<User> response) {
data.setValue(response.body());
}
});
return data;
}
}
Зберігання даних
В нашій поточній реалізації, якщо користувач повертає екран, або виходить та повертається до застосування, існуючий UI буде видимий безпосередньо, оскільки репозиторій отримуж дані від кешу в пам'яті. Але ще відбуватиметься, якщо користувач вийде із застосування, та повернетьтся через годину, після того, як Android OS вже вб'є процес?
В поточній реалізації нам буде треба знову підтягнути дані з мережі. Це не тільки поганий досвід для користувача, але також розтринькує мобільні ресурси для отримання тих самих даних. Ви можете просто полагодити це, через кешування веб запитів, але це створює нові проблеми. Що буде, коли ті самі дані користувача трапляються в іншому типі запитів (наприклад, при отриманні списка друзів)? Тоді, можливо, ваше застосування буде показувати неузгоджені дані, що, в кращому випадку, трохи спантеличить користувача. Наприклад, ті самі дані користувача можуть показуватись інакше, оскільки запит списку друзів, та запит окремого користувача відбувались в різний час. Ваше застосування має поєднати їх, щоб уникнути неузгодженості.
Відповідний спосіб для обробки цього випадку полягає в використанні стійкої моделі. Ось де на допомогу приходить бібліотека стійкості Room.
Room є бібліотекою мепінгу, що провадить локальне зберігання даних з мінімумом загального коду. Під час компіляції вона перевіряє кожний запит відносно схеми, так що поламані запити SQL призведуть до помилок часу компіляції, замість збоїв часу виконання. Room абстрагується від деяких деталей реалізації роботи з сирими SQL таблицями та запитами. Він також дозволяє нагляд за змінами вданих бази даних (включаючи колекції та запити поєднання), показуючи такі зміни через об'єкти LiveData. На додаток, він явно визначає потокові обмеження, що націлені на загальні проблеми, такі, як доступ до сховища в головному потоці.
Щоб використати Room, нам треба визначити нашу власну схему. Перше,
анотуйте клас User за допомогою @Entity,
щоб відмітити його як таблицю в вашій базі даних.
@Entity
class User {
@PrimaryKey
private int id;
private String name;
private String lastName;
// getters and setters for fields
}
Потім створіть клас бази даних, через розширення RoomDatabase
для вашого застосування:
@Database(entities = {User.class}, version = 1)
public abstract class MyDatabase extends RoomDatabase {
}
Зауважте, що MyDatabase є абстрактним. Room автоматично
провадить його реалізацію. Дивіться докуентацію Room
щодо деталей.
Тепер вам треба мати спосіб вставити користувацькі дані в базу даних. Для цього ми створимо об'єкт доступу до даних (data access object, DAO).
@Dao
public interface UserDao {
@Insert(onConflict = REPLACE)
void save(User user);
@Query("SELECT * FROM user WHERE id = :userId")
LiveData<User> load(String userId);
}
Потім посилаємось на DAO з класа бази даних.
@Database(entities = {User.class}, version = 1)
public abstract class MyDatabase extends RoomDatabase {
public abstract UserDao userDao();
}
Зауважте, що метод load повертає LiveData<User>.
Room знає, коли база даних модифікована, та буде автоматично повідомляти
всі активні обсервери при зміні даних. Оскільки він використовує LiveData,
це буде ефективним, оскільки він буде оновлювати дані тільки якщо буде
щонайменше один активний спостерігач.
Тепер ми можемо модифікувати наш UserRepository, щоб
вбудувати джерело даних Room.
@Singleton
public class UserRepository {
private final Webservice webservice;
private final UserDao userDao;
private final Executor executor;
@Inject
public UserRepository(Webservice webservice, UserDao userDao, Executor executor) {
this.webservice = webservice;
this.userDao = userDao;
this.executor = executor;
}
public LiveData<User> getUser(String userId) {
refreshUser(userId);
// повертаємо LiveData напряму з бази даних.
return userDao.load(userId);
}
private void refreshUser(final String userId) {
executor.execute(() -> {
// виконуємо в фоновому потоці
// перевіряємо, чи користувач отримував недавно
boolean userExists = userDao.hasUser(FRESH_TIMEOUT);
if (!userExists) {
// оновлюємо дані
Response response = webservice.getUser(userId).execute();
// TODO перевірити на помилки, тощо
// Оновлення бази даних. LiveData буде автоматично оновлюватись
// так що нам не треба нічого робити, окрім оновлення бази даних
userDao.save(response.body());
}
});
}
}
Зауважте, що навіть якщо ми змінили, звідки потрабляють дані в UserRepository,
нам не треба змінювати наш UserProfileViewModel або
UserProfileFragment. Ця гнучкість провадиться рівнем
абстракції. Це також добре для тестування, бо ви можете провадити
фейковий UserRepository для тестування вашого UserProfileViewModel.
Тепер наш код завершений. Якщо користувач повертається до того самого UI через декілька днів, вони будуть безпосередньо бачити інформацію користувача, оскільки ми зробили її стійкою. Більше того, наш репозитарій буде оновлювати дані в фоні, якщо дані застарілі. Звичайно, в залежності від вашого випадку, ви можете схилитись не показувати збережені дані, якщо вони застарілі.
В деяких випадках, таких, як натиснути-для-оновлення, важливо для
UI показувати користувачу, якщо нараозі відбувається мережева операція.
Є гарною практикою відділяти операції UI від дійсних даних, оскільки
вони можуть бути оновлені за багатьох причин (наприклад, якщо ми
підтягуємо список друзів, тай самий користувач може бути підтягнутий
знову, та спрацює оновлення LiveData<User>). З
перспективи UI факт, що наразі є активний запит, є тільки іншою точкою
даних, подібно до любого іншого фрагменту даних (як об'єкт User).
Існують дві загальні рішення для цього випадку:
- Змініть
getUser, щоб він повертав LiveData, що включає статус мережевої операцїі. Реалізація-приклад надодиться в розділі Додаток: використання мережевого статусу. - Впровадьте іншу публічну фнукцію в класі-репозиторії, що може повертатись стан оновлення до User. Ця опція краще, якщо ви бажаєте показати мережевий статус в вашому UI тільки у відповідь на явну дію користувача (як нажати-щоб-оновити).
Єдине джерело правди
Є загальним для різних ендпоінітів REST API повертати ті самі дані.
Гаприклад, якщо наш бекенд має інший ендпоінт, що повертає список
друзів, той самий об'єкт користувача може поступити від різних
ендпоінтів API, можливо з різними подробицями. Якщо UserRepository
буде повертати відповідь від запиту Webservice як є, наші
UI можуть потенційно показувати різні дані, оскільки дані можуть
змінитись на стороні сервера між ціма запитами. Ось чому в реалізації UserRepository
зворотній виклик веб сервісу тільки зберігає дані в базі даних. Потім
зміни в базі даних спрацьовують тригер зворотнього виклику на активних
об'єктах LiveData objects.
В Цій моделі база даних служить як єдине джерело правди, та інші частини застосування отримують доступ через репозиторій. Не важливо, чи ви використовуєте дисковий кеш, ми рекомендуємо, щоб ваш репозиторій виділяв джерело даних як єдене джерело правди до залишку застосування.
Testing
We've mentioned that one of the benefits of separation is testability. Letssee how we can test each code module.
-
User Interface & Interactions: This will be the only time you need an Android UI Instrumentation test. The best way to test UI code is to create an Espresso test. You can create the fragment and provide it a mock ViewModel. Since the fragment only talks to the ViewModel, mocking it will be sufficient to fully test this UI.
-
ViewModel: The ViewModel can be tested using a JUnit test. You need to mock only the
UserRepositoryto test it. -
UserRepository: You can test the
UserRepositorywith a JUnit test as well. You need to mock theWebserviceand the DAO. You can test that it makes the right web service calls, saves the result into the database and does not make any unnecessary requests if the data is cached and up to date. Since bothWebserviceandUserDaoare interfaces, you can mock them or create fake implementations for more complex test cases.. -
UserDao: The recommended approach for testing DAO classes is using instrumentation tests. Since these instrumentation tests do not require any UI, they will still run fast. For each test, you can create an in-memory database to ensure that the test does not have any side effects (like changing the database files on the disk).
Room also allows specifying the database implementation so you can test itby providing it the JUnit implementation of the
SupportSQLiteOpenHelper. This approach is usually not recommended because the SQLite versionrunning on the device may differ from the SQLite version on your host machine. -
Webservice: It is important to make tests independent from the outside world so even your
Webservicetests should avoid making network calls to your backend. There are plenty of libraries that help with this. For instance, MockWebServer is a great library that can help you create a fake local server for your tests. -
Testing Artifacts Architecture Components provides a maven artifact to control its background threads. Inside the
android.arch.core:core-testingartifact, there are 2 JUnit rules:InstantTaskExecutorRule: This rule can be used to force Architecture Components to instantly execute any background operation on the calling thread.CountingTaskExecutorRule: This rule can be used in instrumentation tests to wait for background operations of the Architecture Components or connect it to Espresso as an idling resource.
The final architecture
The following diagram shows all the modules in our recommended architectureand how they interact with one another:
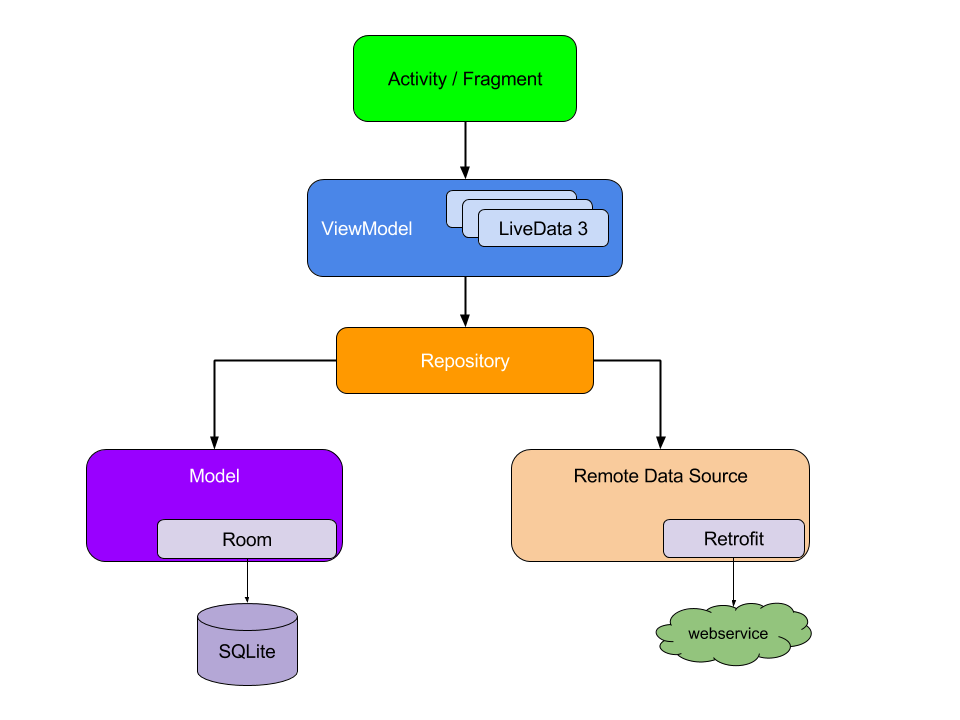
Guiding principles
Programming is a creative field, and building Android apps is not anexception. There are many ways to solve a problem, be it communicating data between multiple activities or fragments, retrieving remote data andpersisting it locally for offline mode, or any number of other common scenarios that non-trivial apps encounter.
While the following recommendations are not mandatory, it has been ourexperience that following them will make your code base more robust, testable and maintainable in the long run.
- The entry points you define in your manifest - activities, services, broadcast receivers, etc. - are not the source of data. Instead, they should only be coordinating the subset of data that is relevant to that entry point. Because each app component is rather short lived, depending on the user's interaction with their device and the overall current health of the runtime, you do not want any of these entry points to be the source of data.
- Be merciless in creating well defined boundaries of responsibility between various modules of your app. For example, don't spread the code that loads data from the network across multiple classes or packages in your code base. Similarly, don't stuff unrelated responsibilities - such as data caching and data binding - into the same class.
- Expose as little as possible from each module. Do not be tempted to create "just that one" shortcut that exposes internal implementation detail from one module. You may gain a bit of time in the short term, but you will be paying technical debt many times over as your codebase evolves.
- As you define the interaction between the modules, think about how to make each one testable in isolation. For example, having a well-defined API for fetching data from the network will make it easier to test the module that persists that data in a local database. If, instead, you mix the logic from these two modules in one place, or sprinkle your networking code across your entire code base, it will be much harder - if not impossible - to test.
- The core of your app is what makes it stand out from the rest. Don't spend your time reinventing the wheel or writing the same boilerplate code again and again. Instead, focus your mental energy on what makes your app unique, and let the Android Architecture Components and other recommended libraries handle the repetitive boilerplate.
- Persist as much relevant and fresh data as possible so that your app is usable when the device is in offline mode. While you may enjoy constant and high speed connectivity, your users might not.
- Your repository should designate one data source as the single source of truth. Whenever your app needs to access this piece of data, it should always originate from the single source of truth. For more information, see Single source of truth.
Addendum: exposing network status
In the recommended
app architecture section above, we intentionally omitted network
error and loading states to keep thesamples simple. In this section, we
demonstrate a way to expose network status using a Resource
class to encapsulate both the data and its state.
Below is a sample implementation:
//a generic class that describes a data with a status
public class Resource<T> {
@NonNull public final Status status;
@Nullable public final T data;
@Nullable public final String message;
private Resource(@NonNull Status status, @Nullable T data, @Nullable String message) {
this.status = status;
this.data = data;
this.message = message;
}
public static <T> Resource<T> success(@NonNull T data) {
return new Resource<>(SUCCESS, data, null);
}
public static <T> Resource<T> error(String msg, @Nullable T data) {
return new Resource<>(ERROR, data, msg);
}
public static <T> Resource<T> loading(@Nullable T data) {
return new Resource<>(LOADING, data, null);
}
}
Because loading data from network while showing it from the disk is a
common use case, we are going to create a helper class NetworkBoundResource
that can be reused in multiple places. Below is the decision tree forNetworkBoundResource:
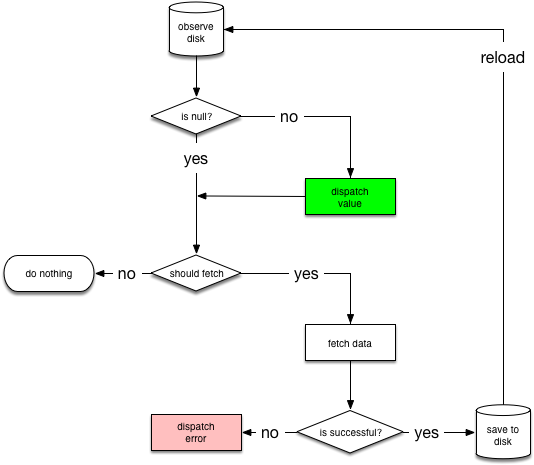
It starts by observing database for the resource. When the entry is
loaded from the database for the first time, NetworkBoundResource
checks whether the result is good enough to be dispatched and/or it
should be fetched fromnetwork. Note that both of these can happen at the
same time since you probably want to show the cached data while updating
it from the network.
If the network call completes successfully, it saves the response into thedatabase and re-initializes the stream. If network request fails, we dispatch a failure directly.
Below is the public API provided by NetworkBoundResource
class for its children:
// ResultType: Type for the Resource data
// RequestType: Type for the API response
public abstract class NetworkBoundResource<ResultType, RequestType> {
// Called to save the result of the API response into the database
@WorkerThread
protected abstract void saveCallResult(@NonNull RequestType item);
// Called with the data in the database to decide whether it should be
// fetched from the network.
@MainThread
protected abstract boolean shouldFetch(@Nullable ResultType data);
// Called to get the cached data from the database
@NonNull @MainThread
protected abstract LiveData<ResultType> loadFromDb();
// Called to create the API call.
@NonNull @MainThread
protected abstract LiveData<ApiResponse<RequestType>> createCall();
// Called when the fetch fails. The child class may want to reset components
// like rate limiter.
@MainThread
protected void onFetchFailed() {
}
// returns a LiveData that represents the resource, implemented
// in the base class.
public final LiveData<Resource<ResultType>> getAsLiveData();
}
Notice that the class above defines two type parameters (ResultType,
RequestType) since the data type returned from the API may
not match the data type used locally.
Also notice that the code above uses ApiResponse for
network request. ApiResponse is a simple wrapper around Retrofit2.Call
class to convert its response into a LiveData.
Below is the rest of the implementation for the NetworkBoundResource
class:
public abstract class NetworkBoundResource<ResultType, RequestType> {
private final MediatorLiveData<Resource<ResultType>> result = new MediatorLiveData<>();
@MainThread
NetworkBoundResource() {
result.setValue(Resource.loading(null));
LiveData<ResultType> dbSource = loadFromDb();
result.addSource(dbSource, data -> {
result.removeSource(dbSource);
if (shouldFetch(data)) {
fetchFromNetwork(dbSource);
} else {
result.addSource(dbSource,
newData -> result.setValue(Resource.success(newData)));
}
});
}
private void fetchFromNetwork(final LiveData<ResultType> dbSource) {
LiveData<ApiResponse<RequestType>> apiResponse = createCall();
// we re-attach dbSource as a new source,
// it will dispatch its latest value quickly
result.addSource(dbSource,
newData -> result.setValue(Resource.loading(newData)));
result.addSource(apiResponse, response -> {
result.removeSource(apiResponse);
result.removeSource(dbSource);
//noinspection ConstantConditions
if (response.isSuccessful()) {
saveResultAndReInit(response);
} else {
onFetchFailed();
result.addSource(dbSource,
newData -> result.setValue(
Resource.error(response.errorMessage, newData)));
}
});
}
@MainThread
private void saveResultAndReInit(ApiResponse<RequestType> response) {
new AsyncTask<Void, Void, Void>() {
@Override
protected Void doInBackground(Void... voids) {
saveCallResult(response.body);
return null;
}
@Override
protected void onPostExecute(Void aVoid) {
// we specially request a new live data,
// otherwise we will get immediately last cached value,
// which may not be updated with latest results received from network.
result.addSource(loadFromDb(),
newData -> result.setValue(Resource.success(newData)));
}
}.execute();
}
public final LiveData<Resource<ResultType>> getAsLiveData() {
return result;
}
}
Now, we can use use NetworkBoundResource to write our
disk and network bound User implementation in the
repository.
class UserRepository {
Webservice webservice;
UserDao userDao;
public LiveData<Resource<User>> loadUser(final String userId) {
return new NetworkBoundResource<User,User>() {
@Override
protected void saveCallResult(@NonNull User item) {
userDao.insert(item);
}
@Override
protected boolean shouldFetch(@Nullable User data) {
return rateLimiter.canFetch(userId) && (data == null || !isFresh(data));
}
@NonNull @Override
protected LiveData<User> loadFromDb() {
return userDao.load(userId);
}
@NonNull @Override
protected LiveData<ApiResponse<User>> createCall() {
return webservice.getUser(userId);
}
}.getAsLiveData();
}
}